
我们在Cloudflare的一个大规模数据基础架构挑战是为我们的客户提供HTTP流量分析。我们所有客户都可以通过两种方式使用HTTP分析:
在这篇博文中,我将谈谈去年Cloudflare分析管道的令人兴奋的演变。我将首先介绍旧管道以及我们遇到的挑战。然后,我将描述我们如何利用ClickHouse构建新的和改进的管道的基础。在此过程中,我将分享有关我们如何进行ClickHouse的架构设计和性能调整的详细信息。最后,我期待数据团队将来考虑提供什么。
让我们从旧数据管道开始。
老数据管道架构
之前的管道建于2014年。之前已经在使用CitusDB和更多数据扩展PostgreSQL for CloudFlare Analytics,以及来自Data团队的更多数据博客文章中提到过。 它有以下组件:
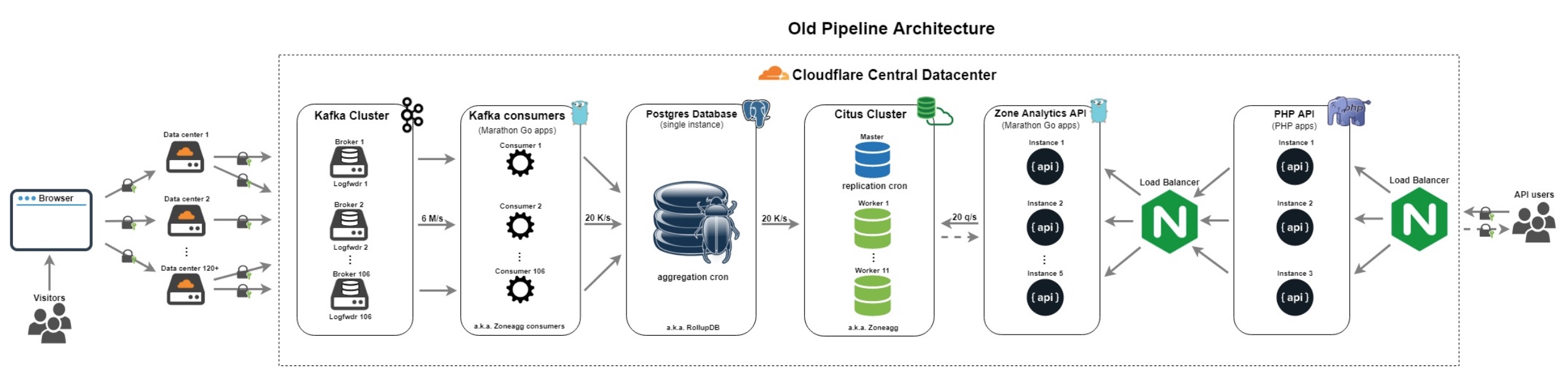
- 日志转发器: 从边缘收集Cap'n Proto格式化日志,特别是DNS和Nginx日志,并将它们发送到Cloudflare中央数据中心的Kafka。
- Kafka集群: 由106个具有x3复制因子的代理组成,106个分区,以平均每秒6M日志的速度摄取Cap'n Proto格式化日志。
- Kafka消费者:106个分区中的每个分区都有专门的Go消费者(又名Zoneagg消费者),每个区域每分钟读取日志并生成聚合,然后将它们写入Postgres。
Postgres数据库:单实例PostgreSQL数据库(又名RollupDB),接受来自Zoneagg使用者的聚合,并按分区每分钟将它们写入临时表。然后,它使用聚合cron将聚合汇总到更多聚合中。进一步来说:
- 每个分区,分钟,区域的聚合→每分钟聚合数据,区域
- 每分钟聚合,区域→每小时聚合数据,区域
- 每小时聚合,区域→每天聚合数据,区域
- 每天聚合,区域→每月聚合数据,区域
Citus Cluster:由Citus master和11位Citus工作者组成,具有x2复制因子(又名Zoneagg Citus集群),Zone Analytics API背后的存储以及我们的BI内部工具。它有复制cron,它将表格从Postgres实例远程复制到Citus工作分片。
- Zone Analytics API:来自内部PHP API的服务查询。它由5个用Go和查询的Citus集群编写的API实例组成,对外部用户不可见。
- PHP API:3个代理API实例,它将公共API查询转发到内部Zone Analytics API,并在区域计划,错误消息等方面具有一些业务逻辑。
- Load Balancer:nginx代理,将查询转发到PHP API / Zone Analytics API。
自从该管道最初于2014年设计以来,Cloudflare已经大幅增长。它开始以每秒1M的请求处理,并且发展到当前每秒6M请求的水平。多年来,管道为我们和我们的客户提供了很好的服务,但在接缝处开始分裂。在需求发生变化时,应在一段时间后重新设计任何系统。
原始管道的一些具体缺点是:
- Postgres SPOF:单个PostgreSQL实例是一个SPOF(单点故障),因为它没有副本或备份,如果我们丢失了这个节点,整个分析管道可能会瘫痪并且不会为Zone Analytics API产生新的聚合。
- Citus master SPOF:Citus master是所有Zone Analytics API查询的入口点,如果它发生故障,我们所有客户的Analytics API查询都会返回错误。
- 复杂的代码库:用于聚合的数千行bash和SQL,以及数千行Go和API和Kafka消费者使得管道难以维护和调试。
- 许多依赖项:由许多组件组成的管道,以及任何单个组件中的故障都可能导致整个管道停止。
- 高昂的维护成本:由于其复杂的架构和代码库,经常发生事故,有时需要数据团队和其他团队的工程师花费数小时来缓解。
随着时间的推移,随着我们的请求数量的增长,操作此管道的挑战变得更加明显,我们意识到这个系统正在被推到极限。这种认识激发了我们思考哪些组件将成为替代的理想候选者,并促使我们构建新的数据管道。
我们的第一个改进分析管道设计以使用Apache Flink流处理系统为中心。我们以前曾使用Flink作为其他数据管道,所以对我们来说这是一个很自然的选择。但是,这些管道的速度远远低于我们需要为HTTP Analytics处理的每秒6M请求,并且我们很难让Flink扩展到此卷 - 它无法跟上每个分区的摄取率每秒所有6M HTTP请求。
我们的DNS团队的同事已经在ClickHouse上构建并生成了DNS分析管道。他们在Cloudflare如何分析每秒1M DNS查询博客文章中写到了这一点。所以,我们决定深入研究一下ClickHouse。
ClickHouse
“ClickHouseнетормозит。”
来自俄语的翻译:ClickHouse没有刹车(或者不慢)
©ClickHouse核心开发者
在探索替换旧管道的一些关键基础架构的其他候选者时,我们意识到使用面向列的数据库可能非常适合我们的分析工作负载。我们希望确定一个面向列的数据库,该数据库具有水平可扩展性和容错性,可以帮助我们提供良好的正常运行时间保证,并且具有极高的性能和空间效率,从而可以处理我们的规模。我们很快意识到ClickHouse可以满足这些标准,然后是一些标准。
ClickHouse是一个面向开源列的数据库管理系统,能够使用SQL查询实时生成分析数据报告。它速度快,线性可扩展,硬件高效,容错,功能丰富,高度可靠,简单易用。ClickHouse核心开发人员在解决问题,合并和维护我们的PR到ClickHouse方面提供了很大的帮助。例如,Cloudflare的工程师在上游贡献了大量代码:
- Marek Vavruša的聚合函数topK
- Marek Vavruša的IP前缀字典
- Marek Vavruša对SummingMergeTree引擎进行了优化
- Kafka Marek Vavruša表引擎。我们想用这个引擎取代Kafka Go的消费者,因为它足够稳定,可以直接从Kafka摄取到ClickHouse。
- 聚合函数sumMap由Alex Bocharov。如果没有此功能,则无法构建新的Zone Analytics API。
- 由Alex Bocharov 标记缓存修复
- uniqHLL12功能修复 Alex Bocharov的大基数。问题的描述及其修复应该是一个有趣的阅读。
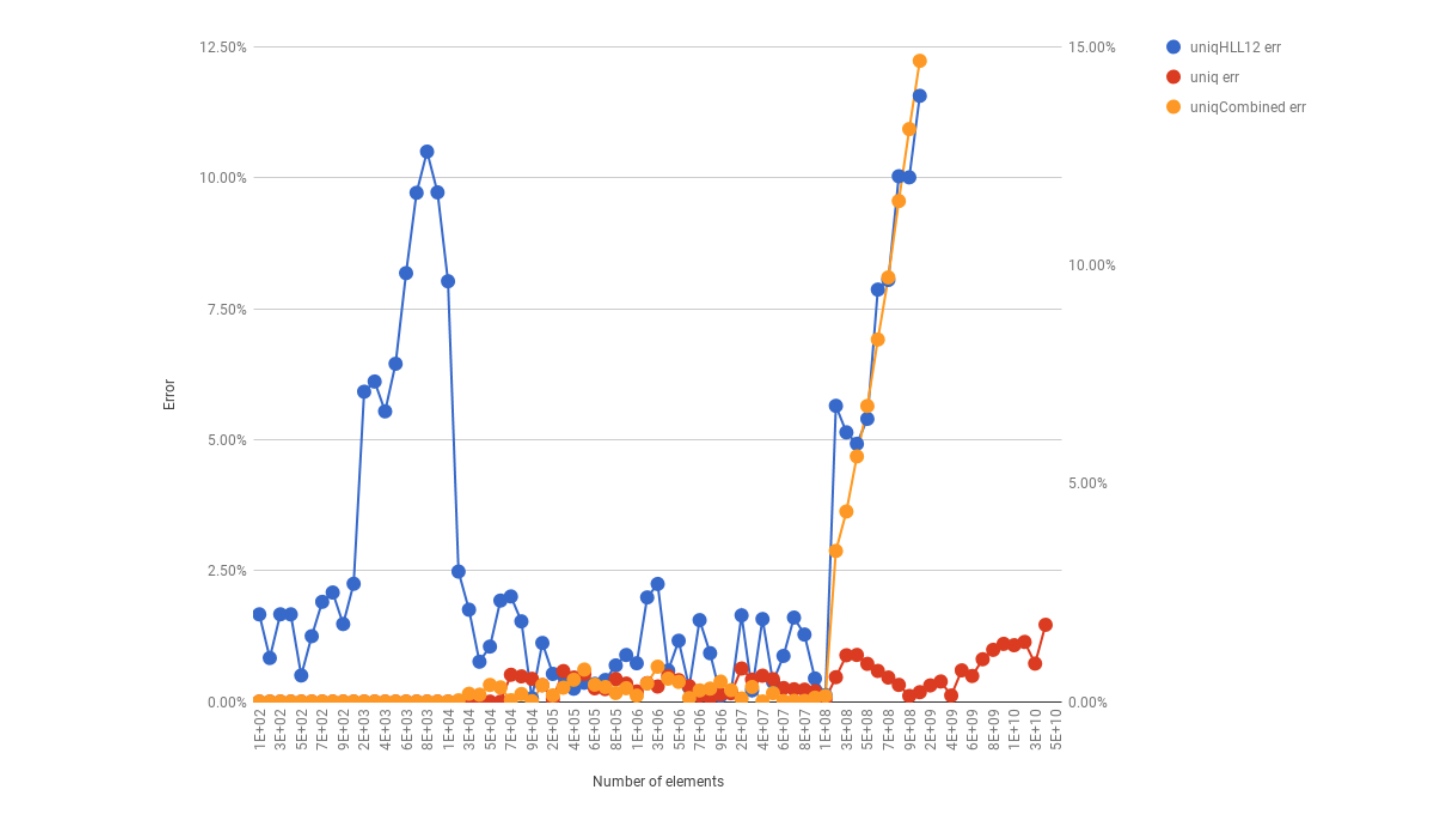
除了提交许多错误报告外,我们还会报告我们在群集中遇到的每个问题,我们希望将来有助于改进ClickHouse。
尽管ClickHouse上的DNS分析取得了巨大成功,但我们仍然怀疑我们是否能够将ClickHouse扩展到HTTP管道的需求:
- 对于HTTP请求主题,Kafka DNS主题平均每秒有1.5M消息,而每秒6M消息。
- 对于HTTP请求主题,Kafka DNS主题平均未压缩消息大小为130B,而对于1630B。
- DNS查询ClickHouse记录包含40列和104列,用于HTTP请求ClickHouse记录。
在尝试使用Flink失败后,我们对ClickHouse能够跟上高摄取率持怀疑态度。幸运的是,早期的原型显示出了良好的性能,我们决定继续进行旧的管道更换。替换旧管道的第一步是为新的ClickHouse表设计一个模式。
ClickHouse架构设计
一旦我们将ClickHouse确定为潜在候选者,我们就开始探索如何移植现有的Postgres / Citus模式以使它们与ClickHouse兼容。
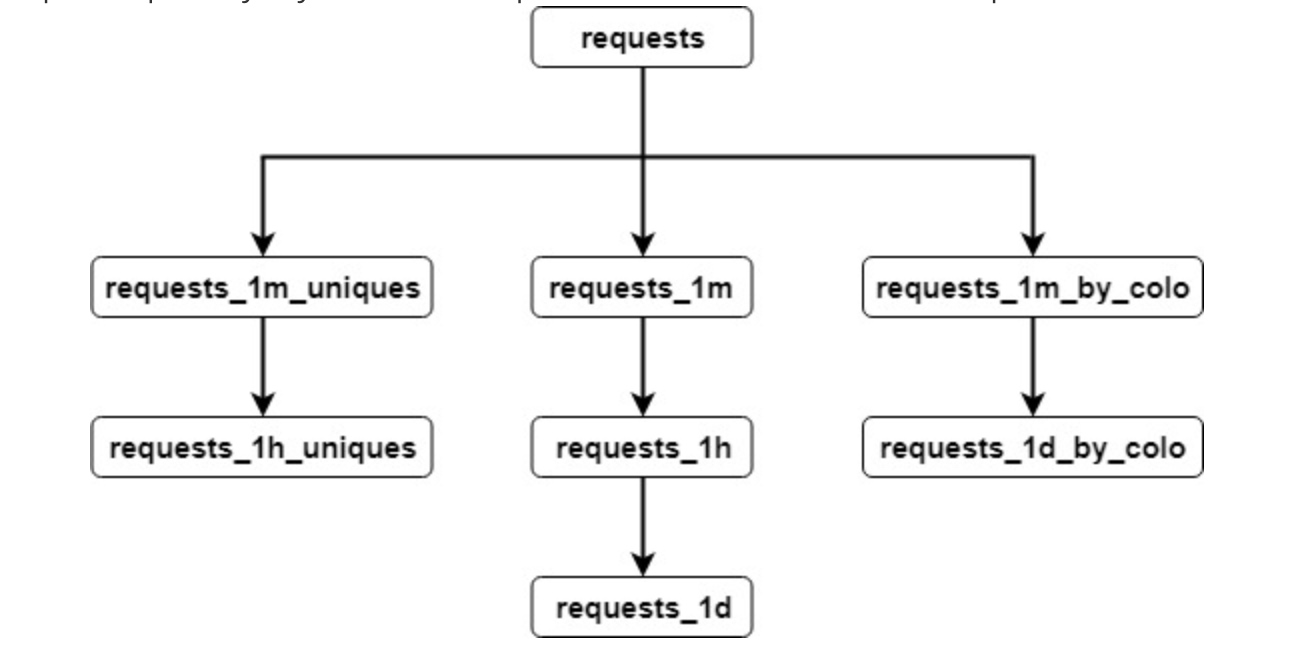
对于我们的Zone Analytics API,我们需要为每个区域(域)和时间段(每分钟/每小时/每日/每月)生成许多不同的聚合。要深入了解聚合的具体信息,请遵循Zone Analytics API文档或此便捷电子表格。
这些聚合应该适用于过去365天的任何时间范围。虽然ClickHouse是一个非常好的工具来处理非聚合数据,但我们的每秒6M请求量,我们只能负担不长时间存储非聚合数据。
为了让您了解这是多少数据,这里有一些“餐巾 - 数学”容量规划。我将使用每秒6M请求的平均插入速率和100美元作为1 TiB的成本估算来计算不同消息格式的1年存储成本:
| Metric | Cap'n Proto | Cap'n Proto (zstd) | ClickHouse |
|---|---|---|---|
| 消息平均大小/记录大小 | 1630 B | 360 B | 36.74 B |
| 存储一年 | 273.93 PiB | 60.5 PiB | 18.52 PiB (RF x3) |
| 存储年费用 | $28M | $6.2M | $1.9M |
那就是如果我们假设每秒的请求将保持不变,但实际上它一直在快速增长。
尽管存储要求非常可怕,但我们仍在考虑将原始(非聚合)请求日志存储在ClickHouse中1个月+。请参阅下面的“数据API的未来”部分。
非聚合请求表
我们存储超过100列,收集有关通过Cloudflare传递的每个请求的大量不同类型的指标。其中一些列也可在我们的Enterprise Log Share产品中使用,但ClickHouse非聚合请求表包含更多字段。
由于存储了如此多的列和巨大的存储要求,我们决定继续使用聚合数据方法,这种方法在旧流水线之前适用于我们,这将为我们提供向后兼容性。
聚合架构设计#1
根据API文档,我们需要提供许多不同的请求细分并满足这些要求,我们决定测试以下方法:
- 使用ReplicatedAggregatingMergeTree引擎创建Cickhouse物化视图,该引擎指向非聚合请求表,并包含每个细分的精确聚合数据:
- 请求总计 - 包含总请求,字节,威胁,唯一身份等数字。
- 按colo的请求 - 包含请求,字节等由edgeColoId细分 - 120多个Cloudflare数据中心
- 按http状态发出的请求 - 包含HTTP状态代码的细分,例如200,404,500等。
- 按内容类型的请求 - 包含按响应内容类型分类,例如HTML,JS,CSS等。
- 按国家/地区的请求 - 包含客户所在国家 /地区的细分(基于IP)
- 威胁类型的请求 - 包含威胁类型的细分
- 浏览器请求 - 包含从用户代理提取的浏览器系列细分
- ip class的请求 - 包含客户端IP类的细分
- 使用两种方法编写来自所有8个物化视图的代码收集数据:
- 使用JOIN一次查询所有8个物化视图
- 分别并行查询8个物化视图中的每一个
- 针对常见的Zone Analytics API查询运行性能测试基准

架构设计#1效果不佳。ClickHouse JOIN语法强制编写超过300行SQL的怪异查询,多次重复所选列,因为您只能在ClickHouse中进行成对连接。
至于并行分别查询每个物化视图,基准显示了显着但温和的结果 - 查询吞吐量比使用基于Citus的旧管道架构要好一点。
聚合架构设计#2
在模式设计的第二次迭代中,我们努力保持与现有Citus表类似的结构。为此,我们尝试使用SummingMergeTree引擎,该引擎由优秀的ClickHouse文档详细描述:
此外,表可以具有以特殊方式处理的嵌套数据结构。如果嵌套表的名称以“Map”结尾,并且它包含至少两列符合以下条件的列...则此嵌套表将被解释为key =>(values ...)的映射,以及合并时它的行,两个数据集的元素由'key'合并为相应的(值...)的总和。
我们很高兴找到这个功能,因为与我们的初始方法相比,SummingMergeTree引擎允许我们显着减少所需的表数。同时,它允许我们匹配现有Citus表的结构。原因是以'Map'结尾的ClickHouse嵌套结构类似于Postgres hstore数据类型,我们在旧管道中广泛使用它。
但是,ClickHouse地图存在两个问题:
- SummingMergeTree对具有相同主键的所有记录进行聚合,但是所有分片的最终聚合应该使用一些聚合函数来完成,而这在ClickHouse中是不存在的。
- 对于存储唯一身份用户(基于IP的唯一访问者),我们需要使用AggregateFunction数据类型,尽管SummingMergeTree允许您创建具有此类数据类型的列,但它不会对具有相同主键的记录执行聚合。
要解决问题#1,我们必须创建一个新的聚合函数sumMap。幸运的是,ClickHouse源代码具有卓越的品质,其核心开发人员非常有助于审查和合并所请求的更改。
对于问题#2,我们必须将uniques放入单独的物化视图中,该视图使用ReplicatedAggregatingMergeTree Engine并支持对具有相同主键的记录合并AggregateFunction状态。我们正在考虑将相同的功能添加到SummingMergeTree中,因此它将进一步简化我们的架构。
我们还为Colo端点创建了一个单独的物化视图,因为它的使用率较低(Colo端点查询为5%,Zone仪表板查询为95%),因此其更分散的主键不会影响Zone仪表板查询的性能。 一旦架构设计可以接受,我们就进行了性能测试。
ClickHouse性能调整
我们在ClickHouse中探索了许多提高性能的途径。这些包括调整索引粒度,并改善SummingMergeTree引擎的合并性能。
默认情况下,ClickHouse建议使用8192索引粒度。有一篇很好的文章深入解释了ClickHouse主键和索引粒度。
虽然默认索引粒度可能是大多数用例的绝佳选择,但在我们的例子中,我们决定选择以下索引粒度:
- 对于主要的非聚合请求表,我们选择了索引粒度为16384.对于此表,查询中读取的行数通常为数百万到数十亿。在这种情况下,较大的索引粒度不会对查询性能产生巨大影响。
- 对于聚合的requests_ * stables,我们选择了索引粒度为32.当我们只需要扫描并返回几行时,低索引粒度是有意义的。它在API性能方面产生了巨大的差异 - 当我们改变索引粒度8192→32时,查询延迟减少了50%,吞吐量增加了~3倍。
与性能无关,但我们还禁用了min_execution_speed设置,因此扫描几行的查询不会返回异常,因为每秒扫描行的速度“慢”。
在聚合/合并方面,我们也进行了一些ClickHouse优化,比如将SummingMergeTree地图的合并速度提高了x7倍,我们将其贡献回ClickHouse以获得每个人的利益。
一旦我们完成了ClickHouse的性能调优,我们就可以将它们整合到一个新的数据管道中。接下来,我们将介绍基于ClickHouse的新数据管道的体系结构。
新数据管道架构
新的管道架构重新使用旧管道中的一些组件,但它取代了其最弱的组件。 新组件包括:
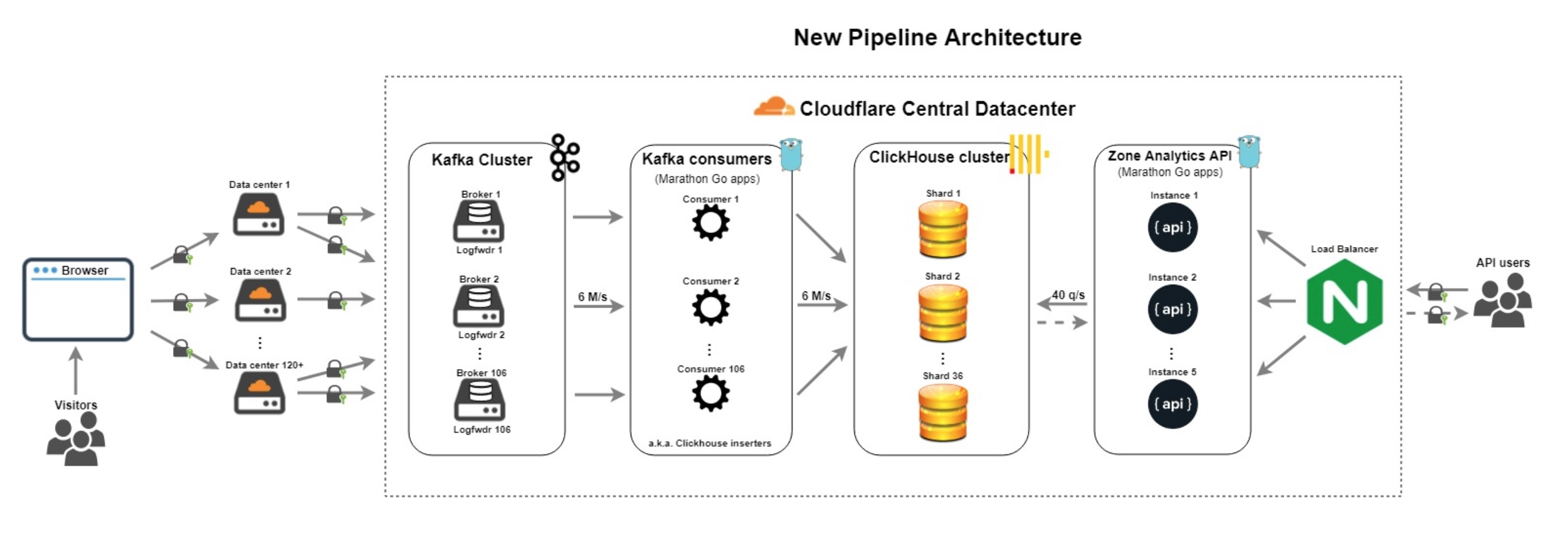
- Kafka消费者 - 每个分区106个消费者使用Cap'n Proto原始日志并提取/准备所需的100多个ClickHouse字段。消费者不再做任何聚合逻辑。
- ClickHouse群集 - 具有x3复制因子的36个节点。它处理非聚合请求日志提取,然后使用物化视图生成聚合。
- Zone Analytics API - Go中重写和优化的API版本,包含许多有意义的指标,运行状况检查和故障转移方案。
正如您所看到的,新管道的体系结构更加简单且容错。它为我们所有7M +客户的域提供分析,每月独立访问量超过25亿,每月页面浏览量超过1.5万亿。
平均而言,我们每秒处理6M HTTP请求,峰值高达每秒8M请求。
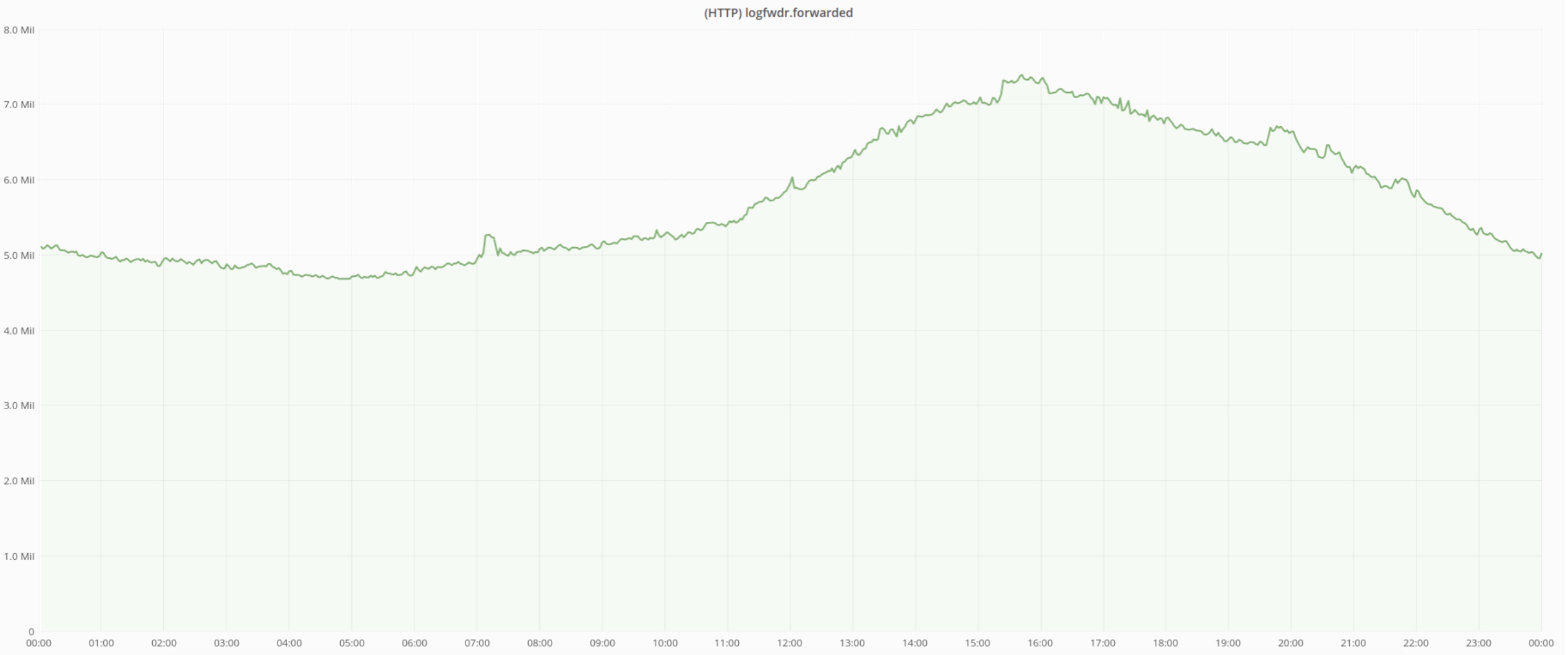
Cap'n Proto格式的 平均日志消息大小曾经是~1630B,但由于我们的平台运营团队对Kafka压缩的惊人工作,它显着下降。请参阅“压缩firehose:从Kafka压缩中获取最多”博客文章,深入了解这些优化。
新管道的好处
- 没有SPOF - 删除所有SPOF和瓶颈,一切至少有x3复制因子。
- 容错 - 它更容错,即使Kafka使用者或ClickHouse节点或Zone Analytics API实例失败,它也不会影响服务。
- 可扩展 - 随着我们的发展,我们可以添加更多Kafka代理或ClickHouse节点并扩展摄取。当群集将增长到数百个节点时,我们对查询性能不太有信心。但是,Yandex团队设法将他们的集群扩展到500多个节点,使用两级分片在几个数据中心之间进行地理分布。
降低复杂性 - 由于删除了混乱的crons和消费者正在进行聚合和重构API代码,我们能够:
- 关闭Postgres RollupDB实例并将其释放以供重用。
- 关闭Citus群集12个节点并将其释放以供重用。由于我们不再将Citus用于严重工作负载,因此我们可以降低运营和支持成本。
- 删除成千上万行旧的Go,SQL,Bash和PHP代码。
- 删除WWW PHP API依赖项和额外延迟。
改进的API吞吐量和延迟 - 使用以前的管道Zone Analytics API难以每秒提供超过15个查询,因此我们不得不为最大用户引入临时硬率限制。使用新的管道,我们能够删除硬率限制,现在我们每秒服务约40次查询。我们进一步对新API进行了密集负载测试,并且通过当前的设置和硬件,我们每秒可以提供大约150个查询,并且可以通过其他节点进行扩展。
操作更简单 - 关闭许多不可靠的组件,我们终于可以相对容易地操作此管道。ClickHouse质量在这件事上对我们有很大的帮助。
- 事故数量减少 - 随着新的更可靠的管道,我们现在发生的事故比以前更少,最终减少了通话负担。最后,我们可以在晚上安然入睡:-)。
最近,我们通过更好的硬件进一步提高了新流水线的吞吐量和延迟。我将在下面提供有关此群集的详细信息。
我们的ClickHouse集群
我们总共有36个ClickHouse节点,我们做过一次新硬件大升级。
- 机箱 - 广达D51PH-1ULH机箱代替Quanta D51B-2U机箱(物理空间减少2倍)
- CPU - 40个逻辑内核E5-2630 v3 @ 2.40 GHz而不是32个内核E5-2630 v4 @ 2.20 GHz
- RAM - 256 GB RAM而不是128 GB RAM
- 磁盘 - 12 x 10 TB希捷ST10000NM0016-1TT101磁盘代替12 x 6 TB东芝TOSHIBA MG04ACA600E
- 网络 - MC-LAG中的2 x 25G Mellanox ConnectX-4,而不是2 x 10G Intel 82599ES
我们的平台运营团队注意到,ClickHouse还不能很好地运行异构集群,因此我们需要逐步用新硬件替换现有集群中的所有节点,全部36个。这个过程非常简单,与替换失败的节点没什么不同。问题是ClickHouse没有限制恢复。
以下是有关我们群集的更多信息:
- 平均插入率 - 我们所有的管道每秒汇集11M行。
- 平均插入带宽 - 47 Gbps。
- 每秒平均查询数 - 平均每秒群集服务大约每秒40次查询,频率峰值高达每秒约80次查询。
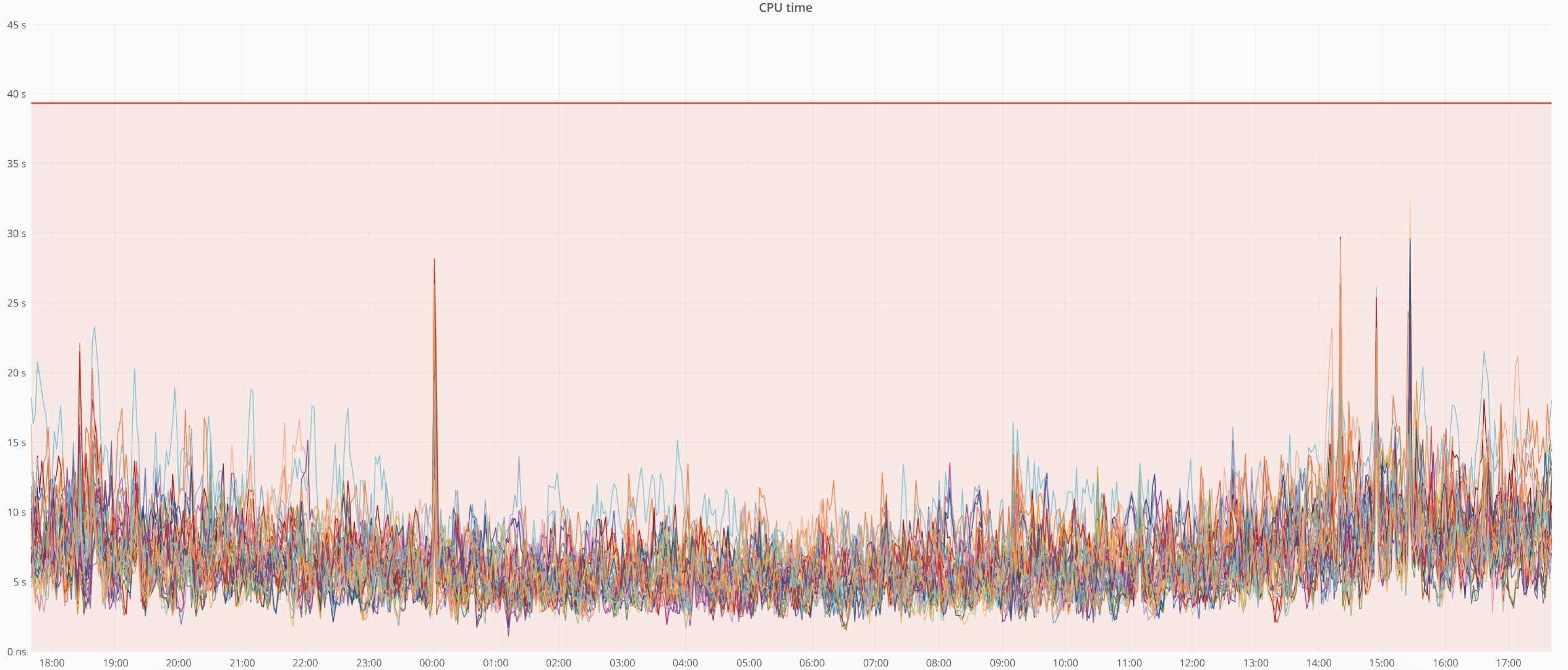
- CPU时间 - 在最近的硬件升级和所有优化之后,我们的集群CPU时间非常短。
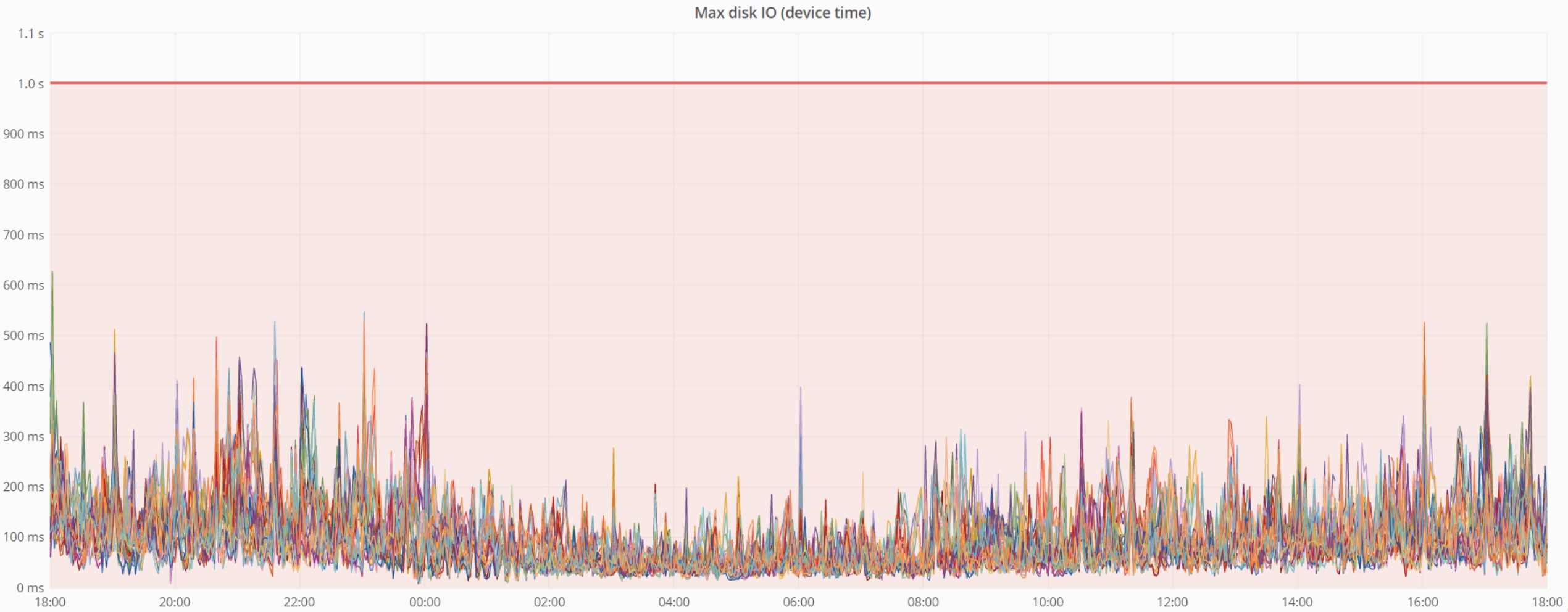
- 最大磁盘IO(设备时间) - 它也很低。
为了尽可能无缝地切换到新管道,我们从旧管道执行历史数据传输。接下来,我将讨论此数据传输的过程。
历史数据传输
由于我们有1年的存储要求,我们不得不从旧的Citus集群到ClickHouse进行一次性ETL(提取转移负载)。
在Cloudflare,我们喜欢Go及其goroutines,因此编写一个简单的ETL工作非常简单,其中:
- 对于每分钟/小时/日/月,从Citus群集中提取数据
- 将Citus数据转换为ClickHouse格式并应用所需的业务逻辑
- 将数据加载到ClickHouse中
整个过程耗时数天,成功传输了超过60亿行数据,并进行了一致性检查。这个过程的完成最终导致了旧管道的关闭。但是,我们的工作并没有就此结束,我们不断展望未来。在下一节中,我将分享一些有关我们计划的细节。
数据API的未来
日志推送
我们目前正在研究一种名为“Log Push”的东西。日志推送允许您指定所需的数据端点,并定期自动发送HTTP请求日志。目前,它处于私人测试状态,并支持将日志发送到:
- 亚马逊S3存储桶
- Google Cloud Service存储桶
- 其他存储服务和平台
预计很快就会推出,但如果您对这款新产品感兴趣并希望试用,请联系我们的客户支持团队。
记录SQL API
我们还在评估构建名为Logs SQL API的新产品的可能性。我们的想法是通过灵活的API为客户提供对日志的访问,该API支持标准SQL语法和JSON / CSV / TSV / XML格式响应。
查询可以提取:
- 原始请求记录字段(例如SELECT field1,field2,... FROM FROM WHERE ...)
- 来自请求日志的聚合数据(例如SELECT clientIPv4,count()FROM请求GROUP BY clientIPv4 ORDER BY count()DESC LIMIT 10)
Google BigQuery提供类似的SQL API,亚马逊也提供产品调用Kinesis数据分析,并支持SQL API。
我们正在探索的另一个选项是提供类似于带有过滤器和维度的DNS Analytics API的语法。
我们很高兴听到您的反馈并了解有关您的分析用例的更多信息。它可以帮助我们构建新产品!

本文由 空心菜 创作,采用 知识共享署名4.0 国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Sep 14, 2018 at 12:20 pm