
之前在文章监控即服务:用于微服务架构的模块化系统我写了关于微服务架构的模块化监控系统的组织。没有什么是静止的,我们的项目在不断增长,存储的指标列表也在增长。在这篇文章中,我将告诉您我们如何组织在高工作负载下的Graphite + Whisper到Graphite + ClickHouse的迁移,关于期望和迁移项目的结果。
在我详细介绍如何组织从Graphite + Whisper中存储指标到Graphite + ClickHouse的迁移之前,我想向您提供一些背景信息,说明这个决定的原因以及我们必须提出的Whisper的缺点很长一段时间。
Graphite + Whisper的问题
1、磁盘子系统高负载
在迁移时,我们每分钟收到大约150万个指标。在该指标流程中,我们的服务器的磁盘利用率约为30%。这是完全可以接受的 - 系统稳定,写入和读取速度足够高......直到其中一个开发团队推出新功能并开始每分钟生成1000万个指标。那时磁盘子系统被拉伸了,我们看到了100%的利用率。问题很快得到解决,但余味仍然存在。
2、缺乏复制和一致性
最有可能的是,像使用或使用Graphite + Whisper的每个人一样,我们将相同的度量标准流程路由到多个Graphite服务器以实现弹性。这并没有引起任何特殊问题 - 直到其中一台服务器出于某种原因崩溃的那一天。有时我们设法以足够快的速度重新启动崩溃的服务器,并且carbon-c-relay设法从缓存中恢复指标,有时不会。在后一种情况下,指标存在差距,我们使用rsync修补它。该程序非常耗时。幸运的是,它并没有经常发生。此外,我们还定期对指标进行随机抽样,并将其与群集相邻节点中相同类型的其他指标进行比较。大约5%的情况下,有几个值不同,我们对此并不太满意。
3、大量的使用空间
由于我们在Graphite中编写了基础架构和业务指标(现在还有Kubernetes指标),因此我们经常在指标中只存在少量值并且整个保留期内创建.wsp文件的情况下自我调整。占用整个预先分配的空间,在我们的情况下约为2 Mb。随着时间的推移,出现了多种类型的文件,并且在生成报告时扫描空数据点需要大量的时间和资源,这进一步加剧了这个问题。
我想指出,上述问题可以使用不同方法处理,效果不同,但收到的数据越多,问题就越严重。
考虑到以上所有(并记住之前的帖子),以及收到的指标数量稳步增长以及希望将所有指标切换到30秒的存储间隔(如果需要 - 最多10秒),我们决定尝试Graphite + ClickHouse作为Whisper的有前途的替代品。
Graphite+ClickHouse的期望
在浏览了几个Yandex聚会后,在阅读了Habr.com上的几篇文章后,在研究了文档并在Graphite中为ClickHouse设置找到了相应的组件之后,我们决定采取行动。
这就是我们想要实现的目标:
- 将磁盘子系统利用率从30%降低到5%,
- 将使用的空间量从1 TB减少到100 GB,
- 能够在服务器上每分钟接收1亿个指标,
- 开箱即用的数据复制和弹性,
- 使该项目易于管理并在合理的时间内完成转换,
- 无需停机即可完成转换。
雄心勃勃,对吧?
Graphite+ClickHouse组件
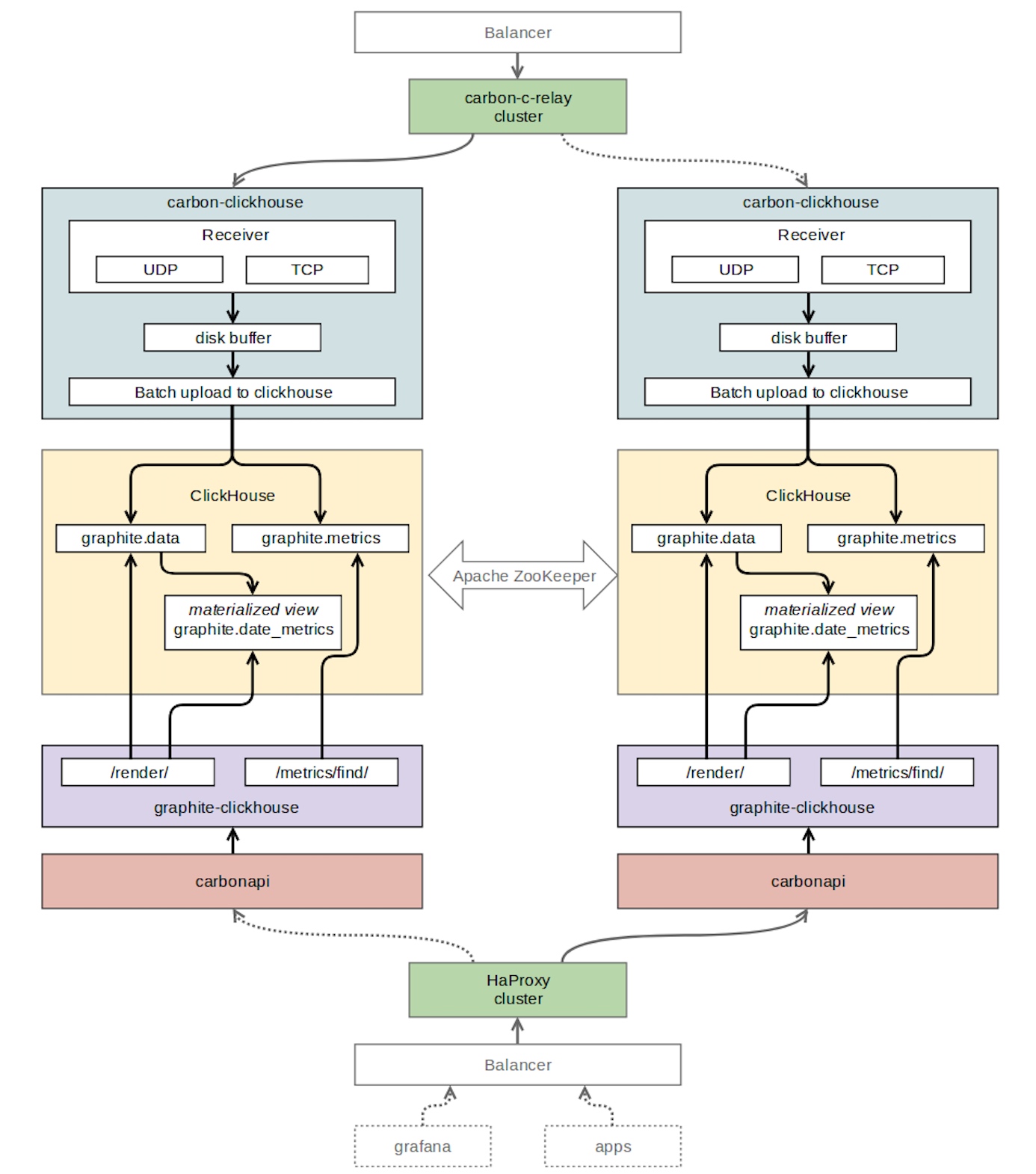
为了使用Graphite协议接收数据然后将其写入ClickHouse,我们选择了carbon-clickhouse(golang)。
作为时间序列存储的数据库,最新的ClickHouse版本的稳定版本1.1.54253被选中。我们遇到了一些问题 - 日志中充满了错误,并不清楚如何处理它。我们选择了旧版本1.1.54236,与Roman Lomonosov(碳点击室,石墨点击室和许多其他东西的作者)合作。错误消失了 - 一切都顺利进行。
要从ClickHouse读取数据,我们选择了graphite-clickhouse(golang)。作为Graphite的API - carbonapi(golang)。为了组织ClickHouse表之间的复制,我们使用了zookeeper。对于指标的路由,我们保留了我们最喜欢的 carbon-c-relay。
Graphite+ClickHouse表结构
“graphite”是我们为监控表创建的数据库。
“graphite.metrics”是一个带有引擎ReplicatedReplacingMergeTree(可复制的ReplacingMergeTree)的表。此表存储度量标准名称和路径。
“graphite.data”是一个带有引擎ReplicatedGraphiteMergeTree(可复制的GraphiteMergeTree)的表。此表存储度量标准值。
“graphite.date_metrics”是一个有条件地填充的表,其引擎为ReplicatedReplacingMergeTree。此表记录了当天遇到的所有指标的名称。创建它的原因在本文后面的“问题”部分中描述。
“graphite.data_stat”是一个有条件地填充的表,其引擎为ReplicatedAggregatingMergeTree(可复制的AggregatingMergeTree)。此表记录传入指标的数量,细分为嵌套级别4。
Graphite+ClickHouse组件交付
Graphite+ClickHouse数据迁移
我们从这个项目的期望中记得,过渡到ClickHouse应该没有停机时间; 因此,我们必须以某种方式将我们的整个监控系统迁移到新的存储库,尽可能透明地为我们的用户。
这就是我们这样做的方式。
•在carbon-c-relay中,添加了一条规则,用于向参与复制ClickHouse表的其中一个服务器的carbon-clickhouse发送额外的度量标准流。
•我们编写了一个小的python脚本,使用whisper-dump库,从我们的存储库中读取所有.wsp文件,并将数据发送到24个线程中的上述carbon-clickhouse。carbon-clickhouse收到的指标数量高达1.25亿/分钟,而ClickHouse很容易处理。
•我们在Grafana中创建了一个单独的DataSource来调试现有仪表板中使用的功能。我们将我们使用的函数列表放在一起,但是在carbonapi中没有实现。我们完成了这些功能,并将PR发送给了carbonapi的作者(他们值得特别感谢)。
•要切换读数负载,请将平衡器设置中的端点从graphite-api(Graphite + Whisper API)重新配置为carbonapi。
Graphite+ClickHouse结果
磁盘子系统利用率从30%降低到1%,
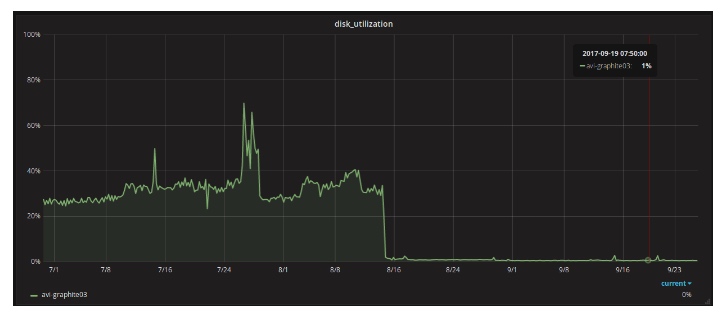
占用的空间量从1 TB减少到300 GB,
•我们每台服务器每分钟可以获得1.25亿个指标(迁移时的峰值),
•所有指标都切换到30秒的存储间隔,
•实现数据复制和弹性,
•无需停机即可完成过渡,
•整个项目在大约7周内完成。
Graphite+ClickHouse问题
我们的项目并非没有陷阱。这是我们在过渡后遇到的情况。
ClickHouse并不总是重新读取配置,有时需要重新启动。例如,在ClickHouse配置中描述zookeeper群集时 - 直到clickhouse-server重新启动才会应用它。
大型ClickHouse查询不起作用,因此我们在graphite-clickhouse中有以下ClickHouse连接字符串:
ClickHouse的新稳定版本经常可用并且可能有错误 - 要小心。
在kubernetes中动态创建的容器发送大量具有短期和随机生命周期的度量。这些指标的数据点很少,并且没有观察到存储空间的问题。但是在构建查询时,ClickHouse会从“指标”表中选择大量这些指标。在90%的情况下,每个插槽(24小时)没有数据。但是,在表'data'中搜索数据需要时间,最终导致超时。为了解决这个问题,我们应用了一个单独的视图,其中包含24小时内遇到的指标信息。因此,当在动态创建的容器上构建报告(图形)时,我们只查询在给定时隙内遇到的那些度量,而不是整个时间,这可以加速报告的生成。对于此解决方案,构建了graphite-clickhouse,包括与date_metrics表的交互实现。
Graphite+ClickHouse标签
从版本1.1.0开始,Graphite正式支持标签。我们正在研究在石墨+ Clickhouse堆栈中为此计划提供支持的内容和方法。

本文由 空心菜 创作,采用 知识共享署名4.0 国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Jul 27, 2018 at 03:51 pm