
引言
我们前面的文章介绍了数字和字符串,比如我计算今天一天的开销花了多少钱我可以用数字来表示,如果是整形用int,如果是小数用float,如果你想记录某件东西花了多少钱,应该使用str字符串型,如果你想记录表示所有开销的物品名称,你应该用什么表示呢?
可能有人会想到我可以用一个较长的字符串表示,把所有开销物品名称写进去,但是问题来了,如果你发现你记录错误了,想删除掉某件物品的名称,那你是不是要在这个长字符串中去查找到,然后删除,这样虽然可行,那是不是比较麻烦呢。
这种情况下,你是不是需要Python给我们提供一种新的数据结构,可以存储很多个字符串,能让我们方便的添加修改和删除,就完美了。
列表(list)同字符串一样都是有序的,因为他们都可以通过切片和索引进行数据访问,列表是可变(mutable)的,你可以修改、更新和删除。
列表是一组有序项目的集合 ,可变的数据类型可 进行增删改查 ; 列表中可以包含Python中任何数据类型和对象,也可包含另一个列表 可任意组合嵌套 列表是以方括号[]包围的数据集合,不同成员以,分隔,列表可通过序号访问其中成员。
列表可以装入Python中所有的对象,看下面的例子就知道:
all_list = [
'nock', # 字符串
1, # 整数
2.0, # 浮点数
print('hello'), # 函数
True, # 布尔值
None, # 空值
[1, 2], # 列表
(3,4), # 元组
{'name': 'nock', 'age': 18} # 字典
]
列表的定义和创建
定义:[]内以逗号分隔,按照索引,存放各种数据类型,每个位置代表一个元素
列表的创建:
第一种:
fruit = ['pineapple', 'pear']
第二种:
fruit = list(['pineapple', 'pear'])
其他数据类型转为列表:
1、把一个字符串转化成列表
>>> alphabet = 'abcd'
>>> alphabet_list = list(alphabet)
>>> alphabet_list
['a', 'b', 'c', 'd']
list在把字符串转换成列表的时候,会把字符串用for循环迭代一下,然后把每个值当作list的一个元素。
2、把元组转换成列表
>>> jobs = ('pm', 'dev', 'qa', 'ops')
>>> jobs_list = list(jobs)
>>> type(jobs_list)
<type 'list'>
>>> jobs_list
['pm', 'dev', 'qa', 'ops']
3、把字典转成列表
>>> age = {'tom': 15, 'jim': 18, 'jerry': 20}
>>> age_list = list(age)
>>> type(age_list)
<type 'list'>
>>> age_list
['jim', 'jerry', 'tom']
>>> values_list = list(age.values())
>>> values_list
[18, 20, 15]
list在把字典转换成列表的时候,默认循环的是字典的key,所以会把key当作列表的元素;如果指定循环的是values,那么就会把values当作列表的元素。
列表的特点和常用方法
特征:
- 多值: 可存放多个值
- 有序: 按照从左到右的顺序定义列表元素,下标从0开始顺序访问

- 可变: 可修改指定索引位置对应的值
列表的增删改查:
增加操作:
# 增 插入 可插入到任何位置
>>> fruit = ['pineapple', 'pear']
>>> fruit.insert(1, 'grape')
>>> fruit
['pineapple', 'grape', 'pear']
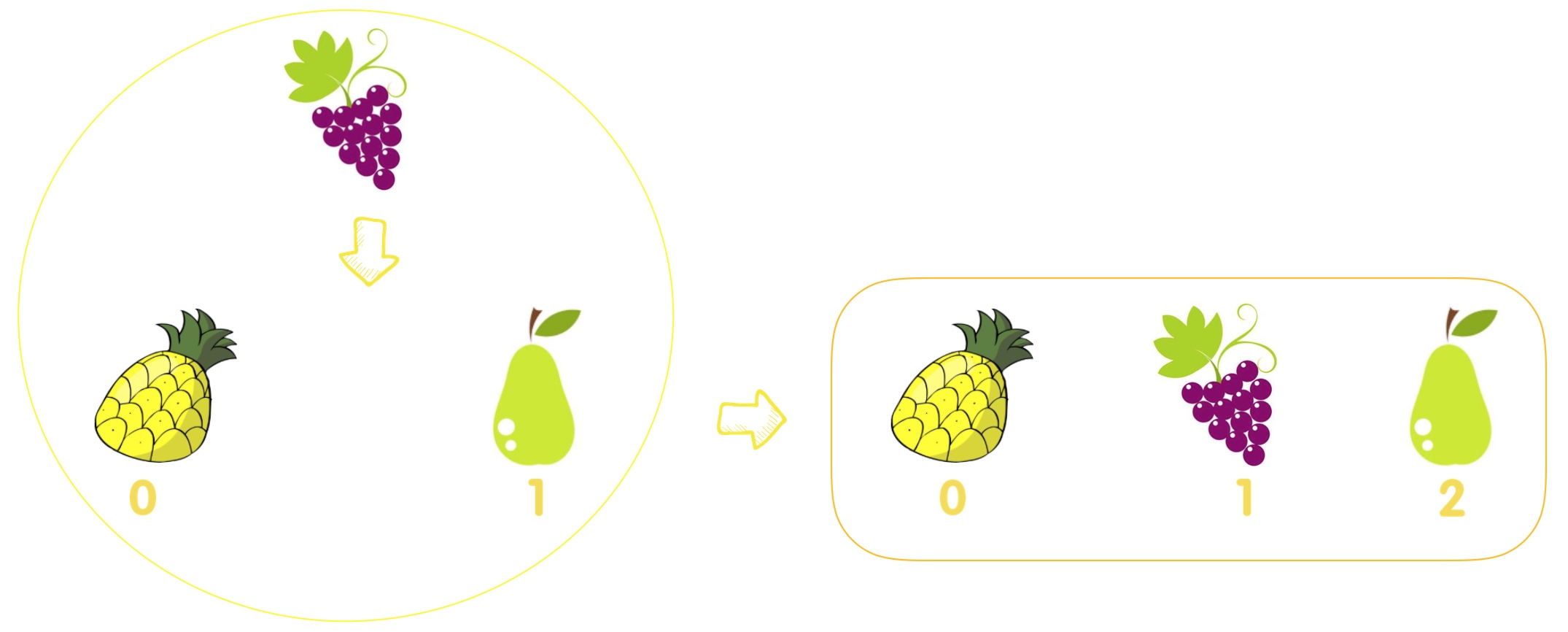
在使用insert方法的时候,必须要指定列表中要插入的新元素的位置,插入元素的实际位置是在指定位置元素的前面的位置,如果指定插入的位置在列表中不存在,实际上也就是超出指定列表的长度,程序运行不会报错,但是这个元素一定会被放到这个列表的最后位置。
>>> fruit = ['pineapple', 'pear']
>>> fruit.insert(4, 'grape')
>>> fruit
['pineapple', 'pear', 'grape']
# 增 append方法 数据会追加到尾部
>>> fruit = ['pineapple', 'pear']
>>> fruit.append('grape')
>>> fruit
['pineapple', 'pear', 'grape']

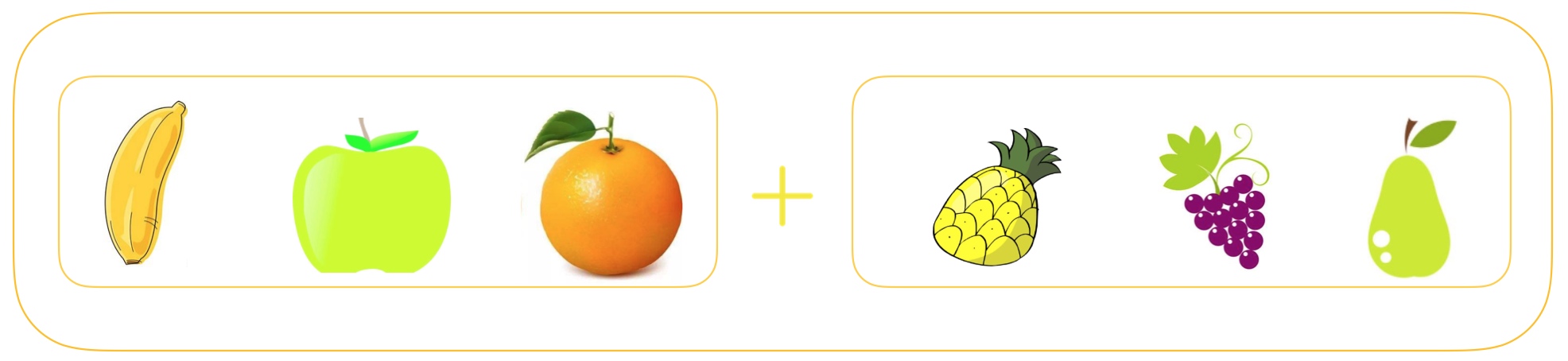
# 合并 extend 把一个列表的值合并到当前一个列表中
>>> fruit_one = ['banana', 'apple', 'orange']
>>> fruit_two = ['pineapple', 'grape', 'pear']
>>> fruit_one.extend(fruit_two)
>>> fruit_one
['banana', 'apple', 'orange', 'pineapple', 'grape', 'pear']
删除操作:
# del 直接删除
>>> jobs = ['PM', 'UI', 'QA', 'OPS']
>>> del jobs[0]
>>> jobs
['UI', 'QA', 'OPS']
# remove 根据remove方法,
>>> jobs = ['PM', 'UI', 'QA', 'OPS']
>>> jobs.remove('PM')
>>> jobs
['UI', 'QA', 'OPS']
# pop 默认删除列表最后一个元素
>>> jobs = ['PM', 'UI', 'QA', 'OPS']
>>> jobs.pop() # pop方法,默认删除最后一个,返回删除元素
'OPS'
>>> jobs
['PM', 'UI', 'QA']
>>> help(jobs.pop)
Help on built-in function pop:
pop(...) method of builtins.list instance
L.pop([index]) -> item -- remove and return item at index (default last).
Raises IndexError if list is empty or index is out of range.
>>> jobs.pop(1) # pop还可以指定元素下标,指定删除
'UI'
>>> jobs
['PM', 'QA']
# clear 方法清空一个列表
>>> jobs = ['PM', 'UI', 'QA', 'OPS']
>>> jobs.clear()
>>> jobs
[]
remove方法删除一个元素,必须是在列表中的,否则会报错,del利用下标来删除元素,pop默认删除最后一个元素,也可以指定元素下标来删除。
修改操作:
>>> jobs = ['PM', 'UI', 'UE', 'OPS', 'DBA', 'DEV']
>>> jobs[2] = 'QA' # 把下标为2的元素替换成QA,根据下标然后给元素重新赋值
>>> jobs
['PM', 'UI', 'QA', 'OPS', 'DBA', 'DEV']
>>> jobs[-2] = 'Sales' # 把下标为12的元素替换成Sales,根据下标然后给元素重新赋值
>>> jobs
['PM', 'UI', 'QA', 'OPS', 'Sales', 'DEV']
查询操作:
>>> jobs = ['PM', 'UI', 'UE', 'OPS', 'DBA', 'DEV']
>>> jobs[1]
'UI'
>>> jobs[2]
'UE'
>>> jobs[4]
'DBA'
>>> jobs[-2] # 还可以倒数着来,不过下标从-1开始
'DBA'
列表索引:
>>> jobs = ['PM', 'UI', 'OPS', 'UE', 'OPS', 'DBA', 'DEV', 'UE']
>>> jobs.index('OPS')
2
>>> jobs.index('UE')
3
>>> jobs.index('xx')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: 'xx' is not in list
>>> if 'OPS' in jobs:
... print(jobs.index('OPS'))
...
2
索引下标,只会返回第一个元素的下标,如果元素不在列表中,会报错,我们可以利用
in这个关键之来判断元素是否在列表中。
列表切片:
>>> jobs = ['PM', 'UI', 'UE', 'OPS', 'DBA', 'DEV']
>>> jobs[1:4] # 取下标从1到4的元素,但是不包括4,列表切片的特征就是左开右闭,也就是左取右弃。
['UI', 'UE', 'OPS']
>>> jobs[1:-1] # 取下标为1到-1的元素,不包括-1,也就是最后一个元素不会被取出来。
['UI', 'UE', 'OPS', 'DBA']
>>> jobs[:] # 这个在切片符左右没有下标限制,所以就是代表全取
['PM', 'UI', 'UE', 'OPS', 'DBA', 'DEV']
>>> jobs[::] # 效果和上面一样,但是你会发现有两切片符,这是因为切片有一个步长的概念
['PM', 'UI', 'UE', 'OPS', 'DBA', 'DEV']
>>> jobs[0:3] # 取下标0到3的元素,但不包括3
['PM', 'UI', 'UE']
>>> jobs[:3] # 和上面效果一样
['PM', 'UI', 'UE']
>>> jobs[3:] # 从下标3开始,到最后一个元素
['OPS', 'DBA', 'DEV']
>>> jobs[3:-1] # 从下标3开始,到最后一个元素,但是不包括最后一个元素
['OPS', 'DBA']
>>> jobs[0::2] # 从下标0开始,按照2个步长取值
['PM', 'UE', 'DBA']
>>> jobs[::2] # 和上面效果一样
['PM', 'UE', 'DBA']
利用下标取出的一个单独元素是str类型,而利用分片取出的是一个list类型。
列表元素统计:
>>> jobs = ['PM', 'UI', 'OPS', 'UE', 'OPS', 'DBA', 'DEV']
>>> jobs.count('OPS') # 因为列表是有序的一种数据类型,所以它的元素是可以重叠的,所以有元素统计。
2
列表排序和翻转:
>>> jobs = ['PM', 'UI', 'OPS', 'UE', 'OPS', 'DBA', 'DEV', 1, 2, 3]
>>> jobs.sort()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unorderable types: int() < str() # Python3.0里不同数据类型不能放在一起排序了,擦
>>> jobs[-1] = '3'
>>> jobs[-2] = '2'
>>> jobs[-3] = '1'
>>> jobs
['DBA', 'DEV', 'OPS', 'OPS', 'PM', 'UE', 'UI', '1', '2', '3']
>>> jobs.sort()
>>> jobs
['1', '2', '3', 'DBA', 'DEV', 'OPS', 'OPS', 'PM', 'UE', 'UI']
>>> jobs.append('#')
>>> jobs.append('&')
>>> jobs.sort()
>>> jobs
['#', '&', '1', '2', '3', 'DBA', 'DEV', 'OPS', 'OPS', 'PM', 'UE', 'UI'] # 可以看出排序的顺序 特殊字符->数字->字母 这么一个优先级
>>> jobs.reverse() # 翻转最后到最前面
>>> jobs
['UI', 'UE', 'PM', 'OPS', 'OPS', 'DEV', 'DBA', '3', '2', '1', '&', '#']
sort()方法会修改原列表,而不是创建一个新的有序列表,reverse()也会修改原列表,但是你希望排序,但是又不希望修改原列表,你只能利用Python中一个名为sorted()的内置函数来操作:
>>> jobs = ['UI', 'UE', 'PM', 'OPS', 'OPS', 'DEV', 'DBA', '3', '2', '1', '&', '#']
>>> newlist = sorted(jobs)
>>> jobs
['UI', 'UE', 'PM', 'OPS', 'OPS', 'DEV', 'DBA', '3', '2', '1', '&', '#']
>>> newlist
['#', '&', '1', '2', '3', 'DBA', 'DEV', 'OPS', 'OPS', 'PM', 'UE', 'UI']
列表拷贝:
>>> jobs
['PM', 'UI', 'UE', 'OPS', 'DBA', 'DEV']
>>> jobs_copy = jobs.copy() # 复制一份jobs列表
>>> jobs_copy
['PM', 'UI', 'UE', 'OPS', 'DBA', 'DEV']
>>> jobs = ['PM', 'UI', 'UE', 'OPS', ['DBA', 'QA', 'DEV']] # 嵌入式列表
>>> jobs_copy2 = jobs.copy()
>>> jobs_copy2
['PM', 'UI', 'UE', 'OPS', ['DBA', 'QA', 'DEV']]
>>> jobs[0] = 'HR' # 改变小标为0的元素
>>> jobs
['HR', 'UI', 'UE', 'OPS', ['DBA', 'QA', 'DEV']] # 改变了
>>> jobs_copy2
['PM', 'UI', 'UE', 'OPS', ['DBA', 'QA', 'DEV']] # 没变
>>> jobs[-1][0] = 'Sales' # 改变内嵌列表的下标为0的元素
>>> jobs
['HR', 'UI', 'UE', 'OPS', ['Sales', 'QA', 'DEV']] # 改变了
>>> jobs_copy2
['PM', 'UI', 'UE', 'OPS', ['Sales', 'QA', 'DEV']] # 改变了
从上面可以看出列表的copy方法是一个浅copy的栗子,只会拷贝第一次,而多层嵌入的话,会随着源列表的变化为变化,关于深拷贝和浅拷贝后面详细介绍。
列表所有的方法如下:
class list(object):
"""
list() -> new empty list
list(iterable) -> new list initialized from iterable's items
"""
def append(self, p_object): # real signature unknown; restored from __doc__
""" L.append(object) -> None -- append object to end """
pass
def clear(self): # real signature unknown; restored from __doc__
""" L.clear() -> None -- remove all items from L """
pass
def copy(self): # real signature unknown; restored from __doc__
""" L.copy() -> list -- a shallow copy of L """
return []
def count(self, value): # real signature unknown; restored from __doc__
""" L.count(value) -> integer -- return number of occurrences of value """
return 0
def extend(self, iterable): # real signature unknown; restored from __doc__
""" L.extend(iterable) -> None -- extend list by appending elements from the iterable """
pass
def index(self, value, start=None, stop=None): # real signature unknown; restored from __doc__
"""
L.index(value, [start, [stop]]) -> integer -- return first index of value.
Raises ValueError if the value is not present.
"""
return 0
def insert(self, index, p_object): # real signature unknown; restored from __doc__
""" L.insert(index, object) -- insert object before index """
pass
def pop(self, index=None): # real signature unknown; restored from __doc__
"""
L.pop([index]) -> item -- remove and return item at index (default last).
Raises IndexError if list is empty or index is out of range.
"""
pass
def remove(self, value): # real signature unknown; restored from __doc__
"""
L.remove(value) -> None -- remove first occurrence of value.
Raises ValueError if the value is not present.
"""
pass
def reverse(self): # real signature unknown; restored from __doc__
""" L.reverse() -- reverse *IN PLACE* """
pass
def sort(self, key=None, reverse=False): # real signature unknown; restored from __doc__
""" L.sort(key=None, reverse=False) -> None -- stable sort *IN PLACE* """
pass
列表推导式:
列表推导式(又称列表解析式)提供了一种简明扼要的方法来创建列表,它的语法简单,很有实用价值。
它的结构是在一个中括号里包含一个表达式,然后是一个for语句,然后是0个或多个for或者if语句。那个表达式可以是任意的,意思是你可以在列表中放入任意类型的对象。返回结果将是一个新的列表,在这个以if和for语句为上下文的表达式运行完成之后产生。
列表解析的一般形式:
[expr for item in itratorable]
L = [x**2 for x in range(10)]
print(L)
Result:
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
列表解析返回的是列表, 列表的内容是表达式执行的结果.
[expr for item in iterable if cond]
[x ** 0.5 for x in range(10) if x % 2 == 0]
[0.0, 1.4142135623730951, 2.0, 2.449489742783178, 2.8284271247461903]
[expr for item in iterable if cond1 if cond2]
[x for x in range(10) if x % 2 == 0 if x > 1]
[2, 4, 6, 8]
[expr for item1 in iterable1 for item2 in iterable2]
[(x, y) for x in range(10) for y in range(10) if (x+y) %2 == 0]
列表解析用于对可迭代对象做过滤和转换,返回值是列表.
特性一: 代码变短,可读性更好
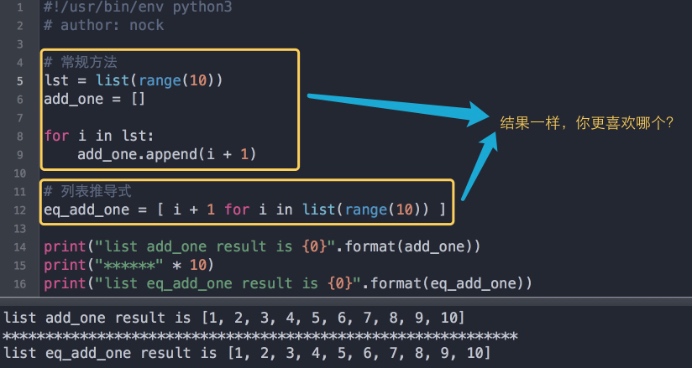
从上图代码示例中我们明显可以看出,列表推导式相比常规方法,写出来的代码更加符合pythonic,更加简短,可读性更好。
有些人甚至更喜欢使用它而不是filter函数生成列表,但是当你使用列表推导式效果会更加,列表推导式在有些情况下超赞,特别是当你需要使用for循环来生成一个新列表.
特征二: 推导式速度更快
#!/usr/bin/env python3
# author: nock
import timeit
lst = list(range(10))
# 常规方法
def origin(lst):
plus_one = []
for i in lst:
plus_one.append(i + 1)
return plus_one
# 列表推导式
def fast(lst):
return [ x + 1 for x in lst ]
otime = timeit.timeit('origin(range(10))', globals=globals())
print("func origin exec time is {0}".format(otime))
ftime = timeit.timeit('fast(range(10))', globals=globals())
print("func origin exec time is {0}".format(ftime))
结果:
func origin exec time is 2.1059355960023822
func origin exec time is 1.6507169340038672
如果你使用map或者filter结合lambda生成列表,也是没有列表推导式速度快的,有兴趣的可以自己Coding一下。
列表的遍历
在Python中常用循环对象来遍历列表,在这里for循环自动调用next()方法,将该方法的返回值赋予给循环对象。循环检测到StopIteration的时候才结束。相对于序列,用循环对象的好处在于:不用在循环还没有开始的时候,就生成好要使用的元素。所使用的元素可以在循环过程中逐次生成。这样,节省了空间,提高了效率,编程更灵活。
1. for循环遍历
#!/usr/bin/env python3
map_list = ['China', 'America', 'Japan', 'Korea']
for countries in map_list:
print(countries) # 自动调用迭代器,自动检测StopIteration
# 在上面的程序中,无法知道当前访问元素的索引,于是有如下代码:
for index in range(len(map_list)):
print("key is %s index is %s" % (map_list[index], index))
2. while循环遍历
#!/usr/bin/env python3
map_list = ['China', 'America', 'Japan', 'Korea']
index = 0
while index < len(map_list):
print(index, map_list[index])
index+=1
3. 拉链(zip)方法遍历
#!/usr/bin/env python3
map_list = ['China', 'America', 'Japan', 'Korea']
for index, value in zip(range(len(map_list)), map_list):
print(index, value)
4. 利用Python内置函数enumerate()列举
enumerate(iterable [, start ]) 返回枚举对象, 参数:
- iterable: 一个序列、迭代器或其他支持迭代的对象
- start: 下标起始位置
#!/usr/bin/env python3
map_list = ['China', 'America', 'Japan', 'Korea']
for value in enumerate(map_list):
print(value)
5. 使用iter()迭代器
iter(collection [, sentinel ]) 函数用来生成迭代器,返回迭代对象, 参数:
- collection: 支持迭代的集合对象
- sentinel: 如果传递了第二个参数,则参数
object必须是一个可调用的对象(如,函数),此时,iter创建了一个迭代器对象,每次调用这个迭代器对象的__next__()方法时,都会调用object。
#!/usr/bin/env python3
map_list = ['China', 'America', 'Japan', 'Korea']
for value in iter(map_list):
print(value)
由于列表在Python内部的组成方式不同于C语言等,其索引的效率相对较为低下。因此在使用python的过程中,如果需要同时用到序号和元素,最好使用enumerate();当我们不需要使用序号时,在列表上直接进行迭代效率最高。
元组
元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表。
语法: names = ('tom', 'jack', 'andy')
它只有2个方法,一个是count,一个是index:
class tuple(object):
"""
tuple() -> empty tuple
tuple(iterable) -> tuple initialized from iterable's items
If the argument is a tuple, the return value is the same object.
"""
def count(self, value): # real signature unknown; restored from __doc__
""" T.count(value) -> integer -- return number of occurrences of value """
return 0
def index(self, value, start=None, stop=None): # real signature unknown; restored from __doc__
"""
T.index(value, [start, [stop]]) -> integer -- return first index of value.
Raises ValueError if the value is not present.
"""
return 0
列表几种高阶常用场景
1. 解压列表赋值给多个变量
现在有一个包含N个元素的元组或者列表,怎样将它里面的值解压后同时赋值给N个变量?
任何的序列(或者是可迭代对象)可以通过一个简单的赋值语句解压并赋值给多个变量。 唯一的前提就是变量的数量必须跟序列元素的数量一致的。
代码示例:
>>> jobs = ('hr', 'dev', 'ops')
>>> x, y, z = jobs
>>> print(x, y, z)
hr dev ops
>>> data = ['nock', 8, 24, (2001, 12, 28)]
>>> name, shares, size, date = data
>>> print(name, shares, size, date)
nock 8 24 (2001, 12, 28)
>>> date
(2001, 12, 28)
>>> name, shares, size, (year, mon, day) = data
>>> name
'nock'
>>> print(year, mon, day)
2001 12 28
如果变量个数和列表元素的个数不匹配,会产生异常的哦。
代码示例:
>>> jobs = ('hr', 'dev', 'ops')
>>> x, y = jobs
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: too many values to unpack (expected 2)
>>> x, y, z, x = jobs
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: not enough values to unpack (expected 4, got 3)
实际上,这种解压赋值可以用在任何可迭代对象上面,而不仅仅是列表或者元组。 包括字符串,文件对象,迭代器和生成器。
代码示例:
>>> name = 'Jim'
>>> a, b, c = name
>>> a
'J'
>>> b
'i'
有时候,你可能只想解压一部分,丢弃其他的值。对于这种情况Python并没有提供特殊的语法。 但是你可以使用任意变量名去占位,到时候丢掉这些变量就行了。
>>> jobs = [18, 30000, 'duck', 100, (2000, 2, 18)]
>>> age, wage, _, num, _ = jobs
>>> age
18
>>> wage
30000
>>> _
(2000, 2, 18)
你必须保证你选用的那些占位变量名在其他地方没被使用到。
2. 删除列表中相同元素并保持顺序
怎样让一个列表保持元素顺序的同时消除重复的值,如果列表上的值都是hashable类型,那么可以很简单的利用集合或者生成器来解决这个问题,比如:
def dedupe(items):
seen = set()
for item in items:
if item not in seen:
yield item
seen.add(item)
下面是使用上述函数的例子:
>>> def dedupe(items):
... seen = set()
... for item in items:
... if item not in seen:
... yield item
... seen.add(item)
...
>>> nums = [1, 5, 2, 1, 9, 1, 5, 10]
>>> list(dedupe(nums))
[1, 5, 2, 9, 10]
这个方法仅仅在序列中元素为hashable的时候才管用。 如果你想消除元素不可哈希(比如 dict 类型)的序列中重复元素的话,你需要将上述代码稍微改变一下,就像这样:
def dedupe(items, key=None):
seen = set()
for item in items:
val = item if key is None else key(item)
if val not in seen:
yield item
seen.add(val)
这里的key参数指定了一个函数,将序列元素转换成hashable类型。下面是它的用法示例:
>>> a = [ {'x':1, 'y':2}, {'x':1, 'y':3}, {'x':1, 'y':2}, {'x':2, 'y':4}]
>>> list(dedupe(a, key=lambda d: (d['x'],d['y'])))
[{'x': 1, 'y': 2}, {'x': 1, 'y': 3}, {'x': 2, 'y': 4}]
>>> list(dedupe(a, key=lambda d: d['x']))
[{'x': 1, 'y': 2}, {'x': 2, 'y': 4}]
如果你想基于单个字段、属性或者某个更大的数据结构来消除重复元素,第二种方案同样可以胜任。
如果你仅仅就是想消除重复元素,通常可以简单的构造一个集合。比如:
>>> a = [1, 5, 2, 1, 9, 1, 5, 10]
>>> list(set(a))
[1, 2, 10, 5, 9]
然而,这种方法不能维护元素的顺序,生成的结果中的元素位置被打乱,而上面的方法可以避免这种情况。
我们使用了生成器函数让我们的函数更加通用,不仅仅是局限于列表处理。 比如,如果如果你想读取一个文件,消除重复行,你可以很容易像这样做:
with open(somefile,'r') as f:
for line in dedupe(f):
...
上述key函数参数模仿了sorted() , min() 和 max()等内置函数的相似功能。
3. 统计列表中出现次数最多的元素
怎样找出一个列表中出现次数最多的元素呢,collections.Counter类就是专门为这类问题而设计的, 它甚至有一个有用的most_common()方法直接给了你答案。
为了演示,先假设你有一个单词列表并且想找出哪个单词出现频率最高。你可以这样做:
>>> from collections import Counter
>>> words = [
... 'look', 'into', 'my', 'eyes', 'look', 'into', 'my', 'eyes',
... 'the', 'eyes', 'the', 'eyes', 'the', 'eyes', 'not', 'around', 'the',
... 'eyes', "don't", 'look', 'around', 'the', 'eyes', 'look', 'into',
... 'my', 'eyes', "you're", 'under'
... ]
>>>
>>> word_counts = Counter(words)
>>> top_three = word_counts.most_common(3)
>>> print(top_three)
[('eyes', 8), ('the', 5), ('look', 4)]
作为输入,Counter对象可以接受任意的由可哈希(hashable)元素构成的序列对象。 在底层实现上,一个Counter对象就是一个字典,将元素映射到它出现的次数上, 比如:
>>> word_counts['not']
1
>>> word_counts['eyes']
8
如果你想手动增加计数,可以简单的用加法:
>>> morewords = ['why','are','you','not','looking','in','my','eyes']
>>> for word in morewords:
... word_counts[word] += 1
...
>>> word_counts['eyes']
9
或者你可以使用 update() 方法:
word_counts.update(morewords)
Counter实例一个鲜为人知的特性是它们可以很容易的跟数学运算操作相结合,比如:
>>> a = Counter(words)
>>> b = Counter(morewords)
>>> a
Counter({'eyes': 8, 'the': 5, 'look': 4, 'into': 3, 'my': 3, 'around': 2,
"you're": 1, "don't": 1, 'under': 1, 'not': 1})
>>> b
Counter({'eyes': 1, 'looking': 1, 'are': 1, 'in': 1, 'not': 1, 'you': 1,
'my': 1, 'why': 1})
>>> # Combine counts
>>> c = a + b
>>> c
Counter({'eyes': 9, 'the': 5, 'look': 4, 'my': 4, 'into': 3, 'not': 2,
'around': 2, "you're": 1, "don't": 1, 'in': 1, 'why': 1,
'looking': 1, 'are': 1, 'under': 1, 'you': 1})
>>> # Subtract counts
>>> d = a - b
>>> d
Counter({'eyes': 7, 'the': 5, 'look': 4, 'into': 3, 'my': 2, 'around': 2,
"you're": 1, "don't": 1, 'under': 1})
毫无疑问, Counter对象在几乎所有需要制表或者计数数据的场合是非常有用的工具。 在解决这类问题的时候你应该优先选择它,而不是手动的利用字典去实现。
4. 过滤列表元素
你有一个数据列表,想利用一些规则从中提取出需要的值或者是缩短列表,最简单的过滤序列元素的方法就是使用列表推导,比如:
>>> nums = [1, 2, -1, 4, 100, -2]
>>> [n for n in nums if n > 0]
[1, 2, 4, 100]
>>> [n for n in nums if n < 0]
[-1, -2]
使用列表推导的一个潜在缺陷就是如果输入非常大的时候会产生一个非常大的结果集,占用大量内存。 如果你对内存比较敏感,那么你可以使用生成器表达式迭代产生过滤的元素,比如:
>>> nums = [1, 2, -1, 4, 100, -2]
>>> num = (n for n in nums if n < 0)
>>> num
<generator object <genexpr> at 0x102210a50>
>>> for n in num:
... print(n)
...
-1
-2
有时候,过滤规则比较复杂,不能简单的在列表推导或者生成器表达式中表达出来。 比如,假设过滤的时候需要处理一些异常或者其他复杂情况。这时候你可以将过滤代码放到一个函数中, 然后使用内建的filter()函数,示例如下:
values = ['1', '2', '-3', '-', '4', 'N/A', '5']
def is_int(val):
try:
x = int(val)
return True
except ValueError:
return False
ivals = list(filter(is_int, values))
print(ivals)
# Outputs ['1', '2', '-3', '4', '5']
filter()函数创建了一个迭代器,因此如果你想得到一个列表的话,就得像示例那样使用list()去转换。
列表推导和生成器表达式通常情况下是过滤数据最简单的方式。 其实它们还能在过滤的时候转换数据,比如:
>>> mylist = [1, 4, -5, 10, -7, 2, 3, -1]
>>> import math
>>> [math.sqrt(n) for n in mylist if n > 0]
[1.0, 2.0, 3.1622776601683795, 1.4142135623730951, 1.7320508075688772]
过滤操作的一个变种就是将不符合条件的值用新的值代替,而不是丢弃它们。 比如,在一列数据中你可能不仅想找到正数,而且还想将不是正数的数替换成指定的数。 通过将过滤条件放到条件表达式中去,可以很容易的解决这个问题,就像这样:
>>> mylist = [1, 4, -5, 10, -7, 2, 3, -1]
>>> clip_neg = [n if n > 0 else 0 for n in mylist]
>>> clip_neg
[1, 4, 0, 10, 0, 2, 3, 0]
>>> clip_pos = [n if n < 0 else 0 for n in mylist]
>>> clip_pos
[0, 0, -5, 0, -7, 0, 0, -1]
另外一个值得关注的过滤工具就是itertools.compress(), 它以一个iterable对象和一个相对应的 Boolean选择器序列作为输入参数。 然后输出iterable对象中对应选择器为True的元素。 当你需要用另外一个相关联的序列来过滤某个序列的时候,这个函数是非常有用的。 比如,假如现在你有下面两列数据:
addresses = [
'5412 N CLARK',
'5148 N CLARK',
'5800 E 58TH',
'2122 N CLARK',
'5645 N RAVENSWOOD',
'1060 W ADDISON',
'4801 N BROADWAY',
'1039 W GRANVILLE',
]
counts = [ 0, 3, 10, 4, 1, 7, 6, 1]
现在你想将那些对应count值大于5的地址全部输出,那么你可以这样做:
>>> from itertools import compress
>>> more5 = [n > 5 for n in counts]
>>> more5
[False, False, True, False, False, True, True, False]
>>> list(compress(addresses, more5))
['5800 E 58TH', '1060 W ADDISON', '4801 N BROADWAY']
这里的关键点在于先创建一个Boolean序列,指示哪些元素符合条件。 然后compress()函数根据这个序列去选择输出对应位置为True的元素。
和filter()函数类似,compress()也是返回的一个迭代器。因此,如果你需要得到一个列表,那么你需要使用list()来将结果转换为列表类型。
5. 列表上索引值迭代
你想在迭代一个列表的同时跟踪正在被处理的元素索引,内置的 enumerate() 函数可以很好的解决这个问题:
>>> my_list = ['a', 'b', 'c']
>>> for idx, val in enumerate(my_list):
... print(idx, val)
...
0 a
1 b
2 c
为了按传统行号输出(行号从1开始),你可以传递一个开始步长值:
>>> my_list = ['a', 'b', 'c']
>>> for idx, val in enumerate(my_list, 1):
... print(idx, val)
...
1 a
2 b
3 c
这种情况在你遍历文件时想在错误消息中使用行号定位时候非常有用:
def parse_data(filename):
with open(filename, 'rt') as f:
for lineno, line in enumerate(f, 1):
fields = line.split()
try:
count = int(fields[1])
...
except ValueError as e:
print('Line {}: Parse error: {}'.format(lineno, e))
enumerate()对于跟踪某些值在列表中出现的位置是很有用的。 所以,如果你想将一个文件中出现的单词映射到它出现的行号上去,可以很容易的利用enumerate()来完成:
word_summary = defaultdict(list)
with open('myfile.txt', 'r') as f:
lines = f.readlines()
for idx, line in enumerate(lines):
# Create a list of words in current line
words = [w.strip().lower() for w in line.split()]
for word in words:
word_summary[word].append(idx)
如果你处理完文件后打印word_summary,会发现它是一个字典(准确来讲是一个defaultdict), 对于每个单词有一个key,每个key对应的值是一个由这个单词出现的行号组成的列表。 如果某个单词在一行中出现过两次,那么这个行号也会出现两次, 同时也可以作为文本的一个简单统计。
当你想额外定义一个计数变量的时候,使用enumerate()函数会更加简单。你可能会像下面这样写代码:
lineno = 1
for line in f:
# Process line
...
lineno += 1
但是如果使用enumerate()函数来代替就显得更加优雅了:
for lineno, line in enumerate(f):
# Process line
...
enumerate()函数返回的是一个enumerate对象实例, 它是一个迭代器,返回连续的包含一个计数和一个值的元组, 元组中的值通过在传入序列上调用next()返回。
还有一点可能并不很重要,但是也值得注意, 有时候当你在一个已经解压后的元组序列上使用enumerate()函数时很容易调入陷阱。 你得像下面正确的方式这样写:
data = [ (1, 2), (3, 4), (5, 6), (7, 8) ]
# Correct!
for n, (x, y) in enumerate(data):
...
# Error!
for n, x, y in enumerate(data):
...
6. 同时迭代多个列表
你想同时迭代多个列表,每次分别从一个序列中取一个元素, 为了同时迭代多个序列,使用zip()函数,比如:
>>> xpts = [1, 5, 4, 2, 10, 7]
>>> ypts = [101, 78, 37, 15, 62, 99]
>>> for x, y in zip(xpts, ypts):
... print(x,y)
...
1 101
5 78
4 37
2 15
10 62
7 99
zip(a, b)会生成一个可返回元组(x, y)的迭代器,其中x来自a,y来自b。 一旦其中某个序列到底结尾,迭代宣告结束。 因此迭代长度跟参数中最短序列长度一致。
>>> a = [1, 2, 3]
>>> b = ['w', 'x', 'y', 'z']
>>> for i in zip(a,b):
... print(i)
...
(1, 'w')
(2, 'x')
(3, 'y')
如果这个不是你想要的效果,那么还可以使用 itertools.zip_longest() 函数来代替,比如:
>>> from itertools import zip_longest
>>> for i in zip_longest(a,b):
... print(i)
...
(1, 'w')
(2, 'x')
(3, 'y')
(None, 'z')
>>> for i in zip_longest(a, b, fillvalue=0):
... print(i)
...
(1, 'w')
(2, 'x')
(3, 'y')
(0, 'z')
当你想成对处理数据的时候 zip() 函数是很有用的。 比如,假设你headers列表和一个values列表,就像下面这样:
headers = ['name', 'shares', 'price']
values = ['ACME', 100, 490.1]
使用zip()可以让你将它们打包并生成一个字典:
s = dict(zip(headers,values))
或者你也可以像下面这样产生输出:
for name, val in zip(headers, values):
print(name, '=', val)
虽然不常见,但是 zip() 可以接受多于两个的序列的参数。 这时候所生成的结果元组中元素个数跟输入序列个数一样, 比如:
>>> a = [1, 2, 3]
>>> b = [10, 11, 12]
>>> c = ['x','y','z']
>>> for i in zip(a, b, c):
... print(i)
...
(1, 10, 'x')
(2, 11, 'y')
(3, 12, 'z')
最后强调一点就是, zip()会创建一个迭代器来作为结果返回。 如果你需要将结对的值存储在列表中,要使用list()函数,比如:
>>> zip(a, b)
<zip object at 0x1007001b8>
>>> list(zip(a, b))
[(1, 10), (2, 11), (3, 12)]
7. 展开嵌透的列表
你想将一个多层嵌套的列表展开成一个单层列表, 可以写一个包含 yield from 语句的递归生成器来轻松解决这个问题。比如:
from collections import Iterable
def flatten(items, ignore_types=(str, bytes)):
for x in items:
if isinstance(x, Iterable) and not isinstance(x, ignore_types):
yield from flatten(x)
else:
yield x
items = [1, 2, [3, 4, [5, 6], 7], 8]
# Produces 1 2 3 4 5 6 7 8
for x in flatten(items):
print(x)
在上面代码中,isinstance(x, Iterable)检查某个元素是否是可迭代的。 如果是的话yield from就会返回所有子例程的值。最终返回结果就是一个没有嵌套的简单列表了。
额外的参数ignore_types和检测语句isinstance(x, ignore_types)用来将字符串和字节排除在可迭代对象外,防止将它们再展开成单个的字符。 这样的话字符串数组就能最终返回我们所期望的结果了。比如:
>>> items = ['Dave', 'Paula', ['Thomas', 'Lewis']]
>>> for x in flatten(items):
... print(x)
...
Dave
Paula
Thomas
Lewis
语句yield from在你想在生成器中调用其他生成器作为子例程的时候非常有用。 如果你不使用它的话,那么就必须写额外的for循环了,比如:
def flatten(items, ignore_types=(str, bytes)):
for x in items:
if isinstance(x, Iterable) and not isinstance(x, ignore_types):
for i in flatten(x):
yield i
else:
yield x
尽管只改了一点点,但是yield from语句看上去感觉更好,并且也使得代码更简洁清爽。
之前提到的对于字符串和字节的额外检查是为了防止将它们再展开成单个字符。 如果还有其他你不想展开的类型,修改参数ignore_types即可。
最后要注意的一点是yield from在涉及到基于协程和生成器的并发编程中扮演着更加重要的角色。
8. 映射名称到列表元素
你有一段通过下标访问列表或者元组中元素的代码,但是这样有时候会使得你的代码难以阅读, 于是你想通过名称来访问元素。
·collections.namedtuple()·函数通过使用一个普通的元组对象来帮你解决这个问题。 这个函数实际上是一个返回Python中标准元组类型子类的一个工厂方法。 你需要传递一个类型名和你需要的字段给它,然后它就会返回一个类,你可以初始化这个类,为你定义的字段传递值等。 代码示例:
>>> from collections import namedtuple
>>> Subscriber = namedtuple('Subscriber', ['addr', 'joined'])
>>> sub = Subscriber('jonesy@example.com', '2012-10-19')
>>> sub
Subscriber(addr='jonesy@example.com', joined='2012-10-19')
>>> sub.addr
'jonesy@example.com'
>>> sub.joined
'2012-10-19'
尽管namedtuple的实例看起来像一个普通的类实例,但是它跟元组类型是可交换的,支持所有的普通元组操作,比如索引和解压。 比如:
>>> len(sub)
2
>>> addr, joined = sub
>>> addr
'jonesy@example.com'
>>> joined
'2012-10-19'
命名元组的一个主要用途是将你的代码从下标操作中解脱出来。 因此,如果你从数据库调用中返回了一个很大的元组列表,通过下标去操作其中的元素, 当你在表中添加了新的列的时候你的代码可能就会出错了。但是如果你使用了命名元组,那么就不会有这样的顾虑。
为了说明清楚,下面是使用普通元组的代码:
def compute_cost(records):
total = 0.0
for rec in records:
total += rec[1] * rec[2]
return total
下标操作通常会让代码表意不清晰,并且非常依赖记录的结构。 下面是使用命名元组的版本:
from collections import namedtuple
Stock = namedtuple('Stock', ['name', 'shares', 'price'])
def compute_cost(records):
total = 0.0
for rec in records:
s = Stock(*rec)
total += s.shares * s.price
return total
命名元组另一个用途就是作为字典的替代,因为字典存储需要更多的内存空间。 如果你需要构建一个非常大的包含字典的数据结构,那么使用命名元组会更加高效。 但是需要注意的是,不像字典那样,一个命名元组是不可更改的。比如:
>>> s = Stock('ACME', 100, 123.45)
>>> s
Stock(name='ACME', shares=100, price=123.45)
>>> s.shares = 75
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: can't set attribute
如果你真的需要改变属性的值,那么可以使用命名元组实例的_replace()方法, 它会创建一个全新的命名元组并将对应的字段用新的值取代。比如:
>>> s = s._replace(shares=75)
>>> s
Stock(name='ACME', shares=75, price=123.45)
_replace()方法还有一个很有用的特性就是当你的命名元组拥有可选或者缺失字段时候, 它是一个非常方便的填充数据的方法。 你可以先创建一个包含缺省值的原型元组,然后使用 _replace() 方法创建新的值被更新过的实例。比如:
from collections import namedtuple
Stock = namedtuple('Stock', ['name', 'shares', 'price', 'date', 'time'])
# Create a prototype instance
stock_prototype = Stock('', 0, 0.0, None, None)
# Function to convert a dictionary to a Stock
def dict_to_stock(s):
return stock_prototype._replace(**s)
下面是它的使用方法:
>>> a = {'name': 'ACME', 'shares': 100, 'price': 123.45}
>>> dict_to_stock(a)
Stock(name='ACME', shares=100, price=123.45, date=None, time=None)
>>> b = {'name': 'ACME', 'shares': 100, 'price': 123.45, 'date': '12/17/2012'}
>>> dict_to_stock(b)
Stock(name='ACME', shares=100, price=123.45, date='12/17/2012', time=None)
最后要说的是,如果你的目标是定义一个需要更新很多实例属性的高效数据结构,那么命名元组并不是你的最佳选择。 这时候你应该考虑定义一个包含 slots 方法的类.

本文由 空心菜 创作,采用 知识共享署名4.0 国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Jul 7, 2019 at 03:17 pm